What is RCU
RCU(Read-Copy-Update)是一种同步机制,用于并发环境。我们通过常见锁同步机制来过渡到 RCU。
首先,常规的锁,包括互斥锁(mutex)和自旋锁(spinlock),它们的特点是不管线程是读还是写,只要进入临界区,就必须独占。效果是读和读之间不能并发,读和写之间也不能并发,所有操作都串行化。
其次,读写锁(reader-writer locks),它的特点是允许多个读之间同时访问,也就是并发读,但一旦有写需要更新,那么所有读就要停下来,让写者独占临界区。效果是读性能比互斥锁好,但读和写之间仍不能并发。
那么,RCU(Read-Copy-Update),它的特点是允许一个写者和多个读者同时并发。它的原理是写者不修改原数据,而是复制一份新版本并更新指针,读者继续无锁访问旧版本,不会被阻塞。等所有读者退出后,旧版本才被安全释放。也就是说 RCU 允许一个写者和多个读者同时运行,读者不会被阻塞,只是可能读到旧版本,但旧版本仍然合法。
seqlock不也允许读者和写者同时进行吗?虽然 seqlock 也允许读者和写者同时运行,但它的并发语义是“乐观但可能重试”;而 RCU 的并发语义是“读者永远成功,只是可能读到旧版本”。
关键 API
rcu_assign_pointer()
观察下面的情形
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
gp = p;在多核CPU和现代编译器中,指令可能会乱序执行或推测优化。上述的代码编译器或CPU可能会把这句提前执行,导致p->a, p->b, p->c 的初始化还没完成就先执行 gp = p 了。
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);这时候就可以利用rcu_assign_pointer() 了,它里面封装了内存屏障(memory barrier)和编译器指令,保证:
- 顺序保证。强制CPU和编译器先完成 p 对象的初始化,而后才更新
gp = p。这样,当读线程通过rcu_dereference(gp)访问时,拿到的gp是已经赋值过的。 - 跨CPU可见性。保证写的更新不会停留在本地CPU的缓存,而是传播到共享内存,在其它CPU上也能看到一致的结果。
- 编译器优化防护。编译器可能会重排指令或推测优化,
rcu_assign_pointer()内部使用了特殊的指令(如barrier()或smp_wmb()),阻止编译器把指针赋值提前。
rcu_dereference()
以上是保证了写者(updater)的操作顺序,保证了gp被写入了正确的内容。但这样还不够,读者(reader)也必须保证访问顺序。举个例子
p = gp;
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}编译器或CPU可能会,还没取到 p 呢,就提前访问p->a, p->b, p->c,那么读者可能就会读到未初始化的数据。
因此,需要使用rcu_dereference() 来取指针,它内部包含必要的内存屏障,能保证:1. 先正确获取指针值,2. 再访问对象字段。
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();用 rcu_read_lock() / rcu_read_unlock() 标记读侧范围,保证旧版本不会在读者使用期间被释放。
有了以上内容,可以保证读者看到的对象一定是完整初始化过的,不会出现“半更新”或未定义数据。读者读到的数据仍然有可能滞后的,这满足 RCU 的设计哲学:允许一个写者和多个读者同时并发,读的内容可能滞后,但保证读的内容完整。
RCU 链表API
在 RCU 中,虽然可以直接用底层原语 rcu_assign_pointer() 和 rcu_dereference() 来构建数据结构,但内核为了简化开发和减少错误,提供了专门的 RCU 链表 API 封装。针对 RCU 的链表API有,list_add_rcu()、list_del_rcu()、list_for_each_entry_rcu()。
其中,写者,用 list_add_rcu() 插入节点,内部封装了 rcu_assign_pointer(),保证先初始化再发布。读者,用 list_for_each_entry_rcu() 遍历链表,内部封装了 rcu_dereference(),保证读到的是合法节点。其中添加锁防止多个写者同时插入,但不会阻止读者并发访问。
插入节点
struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head); // 定义链表头
/* 写者插入新节点 */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
list_add_rcu(&p->list, &head); // RCU 安全插入list_add_rcu() 内部使用了 rcu_assign_pointer(),保证新节点初始化完成后才挂到链表。不过这里需要锁来防止多个写者同时插入,但依旧不会阻塞读者。
删除节点
list_del_rcu(&p->list); // 从链表摘掉节点
synchronize_rcu(); // 等待所有读者退出临界区
kfree(p); // 安全释放节点list_del_rcu() 把节点从链表摘掉,但不会立即释放内存。synchronize_rcu() 等待所有读者完成,确保没有读者再访问旧节点。然后 kfree() 释放内存。
遍历
rcu_read_lock(); // 开始读侧临界区
list_for_each_entry_rcu(p, &head, list) {
do_something(p->a, p->b, p->c);
}
rcu_read_unlock(); // 结束读侧临界区rcu_read_lock() / rcu_read_unlock() 标记读侧临界区,保证旧版本不会在读者使用期间被释放。list_for_each_entry_rcu() 内部使用了 rcu_dereference(),保证读者拿到的节点是合法的。
Wait For Pre-Existing RCU Readers to Complete
根据 RCU 的定义,当调用list_del_rcu() 删除节点时,不能立即释放内存,而是要等待所有读者访问完再删,也就是调用synchronize_rcu() 等待所有读者完成,确保没有读者再访问旧节点。然后再调用 kfree() 释放内存。这是 RCU 中等待的方式。
我们来将它与传统解决等待的方式对比,比如引用计数。引用计数的规则是,每个读者进入时要加一,退出时要减一,写者要释放旧对象时,必须等计数归零。这里可以看出,当进行读操作的时候是需要执行加数减数的。
而 RCU 是不用计数的,那是怎么实现的呢?是通过 宽限期 来保证安全释放。读者进入临界区(通过rcu_read_lock())或者读者退出临界区(通过rcu_read_unlock())是轻量操作,不会加锁或者修改全局计数,写者删除节点后调用synchronize_rcu() 会等待一个宽限期,确保在调用之前已经进入的读侧临界区都结束。等宽限期过去后,写者就可以安全释放旧对象。
这里宽限期和引用计数不同的是,写者不需要知道有多少读者,只要等待所有CPU都退出临界区,就可以安全释放节点。
可以通过这张图来理解等待释放的过程。
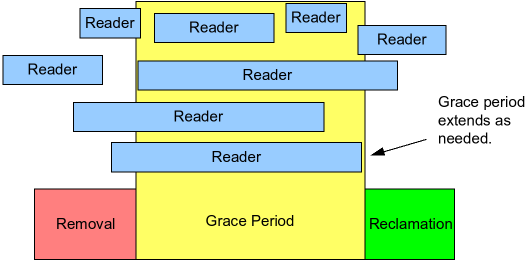
Removal 是写者删除或替换数据的时刻,比如调用list_del_rcu();Grace Period 是等待所有读者完成访问的时间段,也就是宽限期;Reclamation 是安全释放旧数据的时刻,这时可以执行 kfree() 了。
有些读者在 Removal 之前就开始,在 Grace Period 中结束,有些读者在 Grace Period 中开始和结束。箭头所指的读者在 Removal 之后仍然进行,那么宽限期就延长到了它结束。这说明:宽限期必须覆盖所有在 Removal 之前开始的读者,直到它们全部退出临界区为止。
这里有个 trick,RCU 的读侧临界区(由 rcu_read_lock() 和 rcu_read_unlock() 包裹)不允许阻塞或睡眠,这意味着在读者期间线程是不会被调度出去的,也不会进入休眠状态。所以,所以只要发生一次上下文切换,就说明该 CPU 上的读者已经退出临界区。这意味着只要每个 CPU 都执行过一次上下文切换,所有之前的 RCU 读者就都完成了。那么 RCU 等待的条件就不需要跟踪每个读者,而是只需等待每个 CPU 都“轮换”一次。
在非抢占式内核中,
rcu_read_lock()会被编译为空代码,因为读者线程不会被抢占式的调度出去;在抢占式内核中,通过**禁止内核抢占(Disable Kernel Preemption)**来保证读者期间线程不被抢占调度出去。
参考
[What is RCU, Fundamentally? LWN.net[]](https://lwn.net/Articles/262464/)